Managing change is never easy, especially when it comes to data. As a data engineer, you're responsible for ensuring that your dbt projects are up-to-date and accurate. But with data constantly changing, attributes and columns changing, how do you keep up? And more importantly how do you inform your data users? In this guide, we'll explore the challenges of lifecycle management in dbt projects, go over what's good, what can be better and provide some practical tips and tricks to navigate them.
Let's start off with a quick overview of what lifecycle management is.
What is Data Lifecycle Management?
So, what's the deal with data lifecycle management?
It's the process of overseeing the entire lifespan of data, from creation to deletion. Think of it as a roadmap for your data's journey — it starts with data creation, moves through various stages like storage and processing, and eventually reaches its destination, whether that's analysis or retirement.
In this article we'll mostly focus on change management and data deprecation, the aspects of lifecycle management that affect your end-users and data consumers. Data consumers are usually happy to see new data being added to your data model or warehouse but less happy when it unexpectedly changes or disappears. This is why it's important to manage change with effective communication and transparency.
Consequences of Poor Data Lifecycle Management
Not being able to effectively communicate how your data is changing can lead to having a real impact on your business.
Inaccurate, inconsistent, or outdated data can lead to all sorts of problems, from flawed analyses to misguided decision-making. It's like trying to drive with a map that's missing half the roads — it's going to be a bumpy ride and not good for your business.
All off the above can lead to distrust in your data and the data team. This is why it's important to manage change effectively. If you're looking for an all in one solution to manage data docs, including effectively communicating change to your data users, check out refter.
Strategies for Managing Change in dbt Projects
Use dbt model versions
dbt supports versioning of models and transformations, enabling significant changes without disrupting downstream processes. However, it lacks robust features for notifying end-users of these changes.
To learn more about dbt model versions, check out the documentation here.
dbt model deprecation
dbt has a built-in deprecation feature that allows you to mark models as deprecated. It's a great way to communicate to your data users (mostly developers) that a model is going to be removed or changed in the future.
It's mostly intended to communicate that a model version will go away. Deprecation warnings only show up for dbt client users (developers) and not for end-users or stakeholders. That makes them almost invisible to the people that need to know about the changes the most. There's also no way to add additional information about the deprecation.
To add a deprecation warning to a model, add a deprecation_date key to your model properties file. Here's an example:
-- web_sessions.yml
version: 2
models:
- name: web_sessions
description: Number of web sessions per day
deprecation_date: 2024-02-12
refter model deprecation
refter enhances dbt model deprecation by allowing you to configure and append more information. It allows you to communicate changes to both your data users, stakeholders and developers and it will show up in your refter documentation site.
Model deprecation
version: 2
models:
- name: customers
config:
refter: # refter model properties
deprecated:
enabled: true
reason: "We're moving to a new data model"
date: 2024-02-12
Deprecated models will show up in the refter documentation data asset catalog.
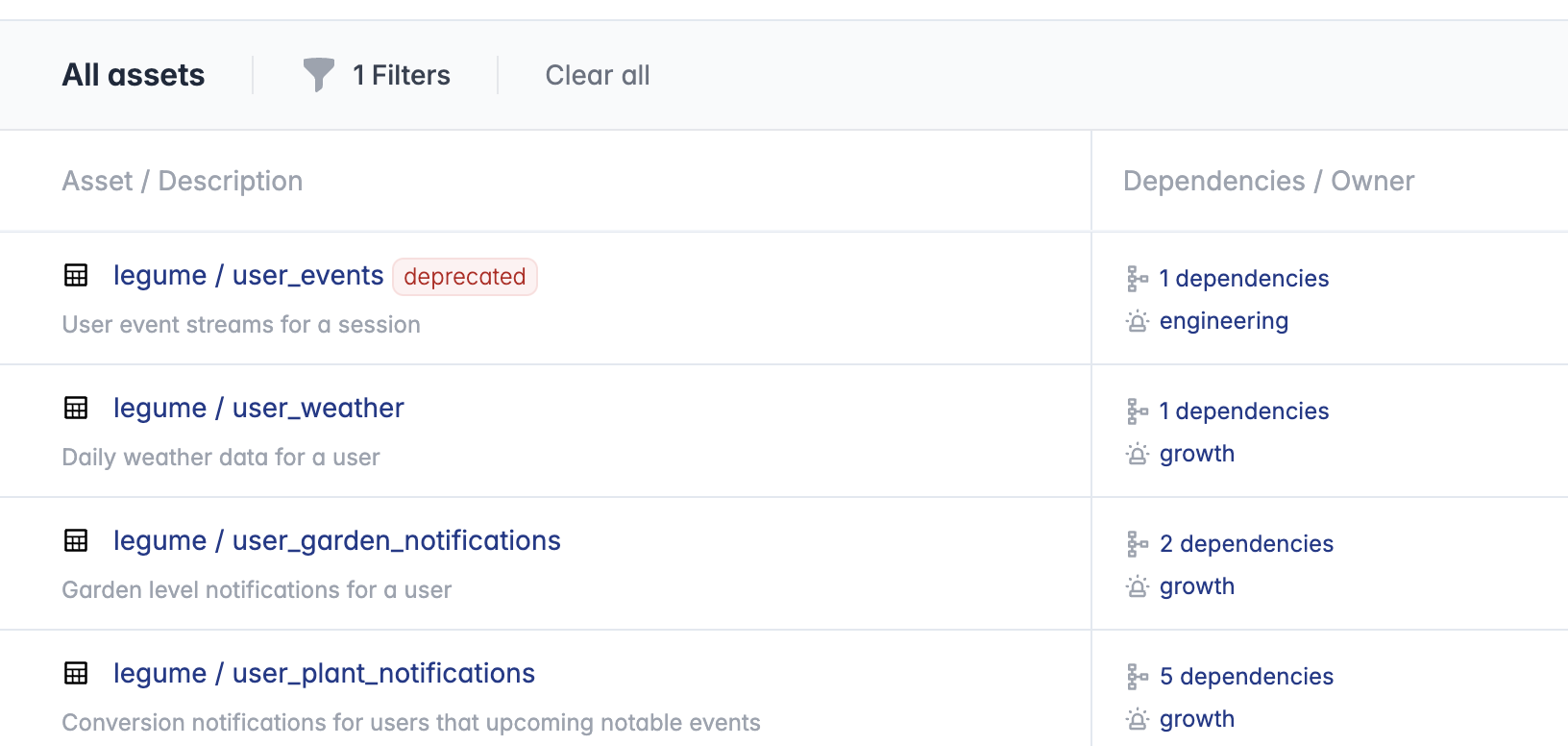
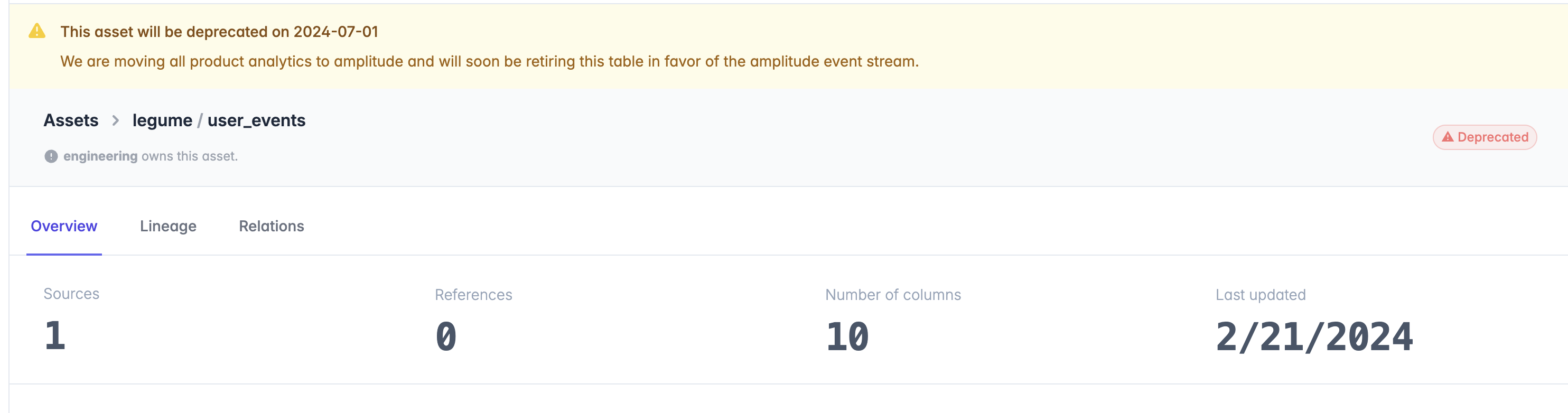
and more information will be provided on the model detail page.
Column deprecation
refter also allows you to deprecate columns. This is a great way to communicate changes to your data users and stakeholders. It's a great way to communicate that a column is going to be removed in the future and point users to the new column.
version: 2
models:
- name: user_events
columns:
- name: id
data_type: int # refter uses dbt data types
tests:
- unique
- not_null
- name: source
data_type: int
refter: # refter column properties
deprecated:
enabled: true
reason: "This column is deprecated, use `order_id` instead"
date: "2021-01-01"
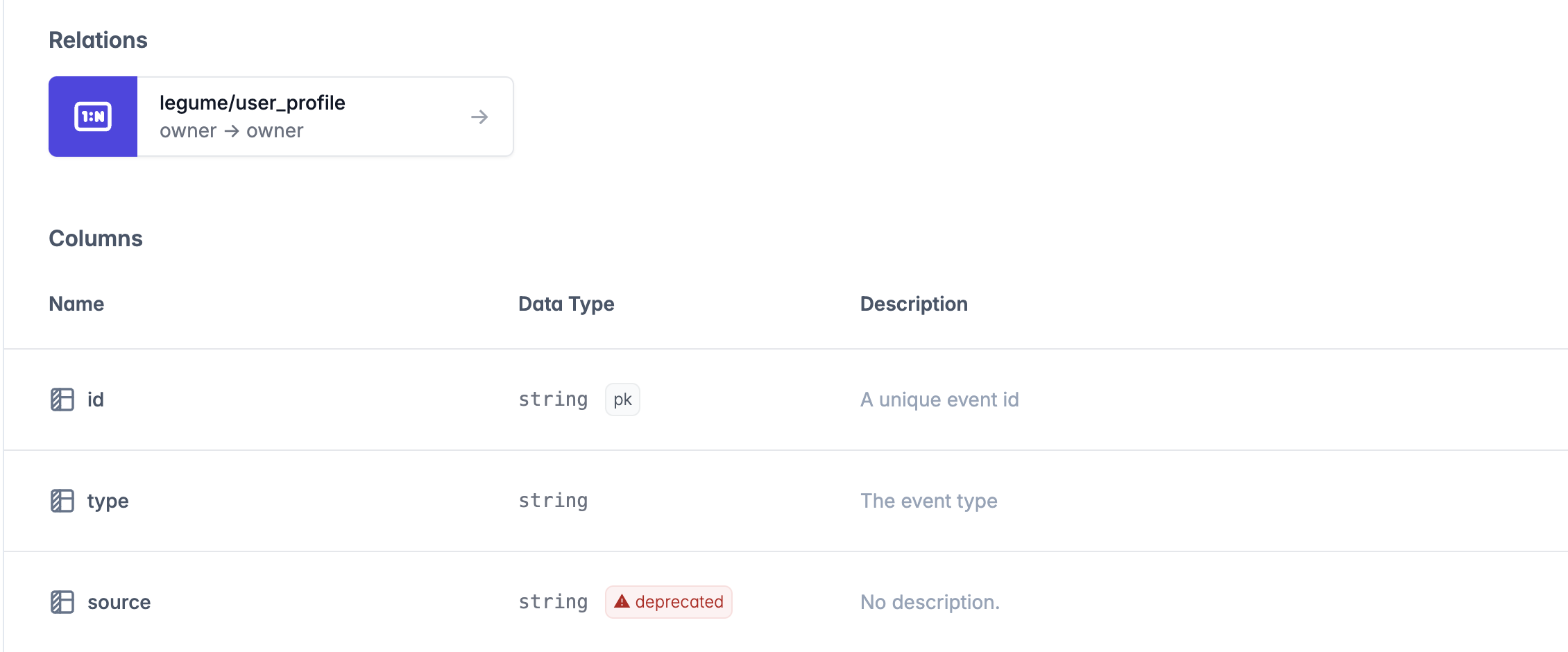
Column deprecation will show up in the refter data documentation site on the asset/model detail page:
Conclusion
dbt offers you some options, but mostly for developers. refter enhances dbt model deprecation by allowing you to configure and append more information. It allows you to communicate changes to both your data users, stakeholders and developers and it will show up in your refter documentation site. This is a great way to manage change in your dbt projects and effectively communicate with your data users and stakeholders.
If you're interested in trying out refter, sign up here for a 30 day free trial.